

基础知识点
- 抓取 Crawling – 寻找新网页或更新后的网页的过程。Google 会通过跟踪链接、读取站点地图或其他各种方式来发现网址。Google 通过抓取网页来寻找新增网页,然后(在适当的时候)将网页编入索引。
- 索引 Indexing – Google 会将所知道的所有网页存储在其索引中。每个网页的索引条目都描述了该网页的内容和位置(网址)。编入索引是指 Google 抓取、读取网页并将其添加到索引的过程。例如:Google 今天已将我网站上的几个网页编入索引。
- 抓取工具或爬虫工具 – 从网络中抓取(提取)网页并将网页编入索引的自动化软件。
- Googlebot – Google 抓取工具的通用名称。Googlebot 会持续不断地抓取网页。也常被称为bot,或者机器人,爬虫,国内由于百度的抓取工具叫Baidu Spider,所有国内也有部分人员习惯把这些爬虫机器人工具叫做蜘蛛。
- SEO – 搜索引擎优化:使你的网站更易于搜索引擎处理的过程;当然也可以指从事搜索引擎优化的人员的职位名称。
抓取 Crawling
抓取是指 Googlebot 访问要添加到 Google 索引中的新网页和更新后的网页的过程。
每时每刻,Google会使用大量计算机提取(即“抓取”)互联网网络上的上亿个网页。执行抓取任务的程序叫做 Googlebot(国内也有叫网络蜘蛛(简称蜘蛛)或者搜索引擎机器人)。Googlebot 使用一定的算法来确定要进行抓取的网站、抓取频率以及要从每个网站抓取的网页数量。
Google 首先会根据一份网页网址列表开始其抓取过程,该列表是在之前进行的抓取过程中生成的,且随着网站所有者所提供的站点地图数据的增多而不断扩大。Googlebot 在访问某个网页时,会查找该网页上的链接,并将这些链接添加到它要抓取的网页的列表中。它会记录新建立的网站、对现有网站进行的更改以及无效链接,并据此更新 Google 索引。
在抓取过程中,搜索引擎机器人会根据网站robots.txt授予的权限,抓取网站相关内容,最后Google 会使用 Chrome 的最新版本呈现网页。在呈现过程中,它会运行找到的所有网页脚本。
在这里要补充一点,由于Googlebot(Google是最大的搜索引擎且占据绝对领先地位,所以这里以Googlebot做举例参考,其他搜索引擎机器人也同理)现在已经已经兼任抓取和呈现网页内容两个重要工作,这里就有一点要说明,我们设计出来的网站目标网页,和最终网站用户,访客看到的网站目标网页中间是由Googlebot来抓取并反馈呈现到用户在浏览器中看到的网页样式,用户看到的网页内容和我们设计的网页内容有没有可能是不一样的?完全有可能!
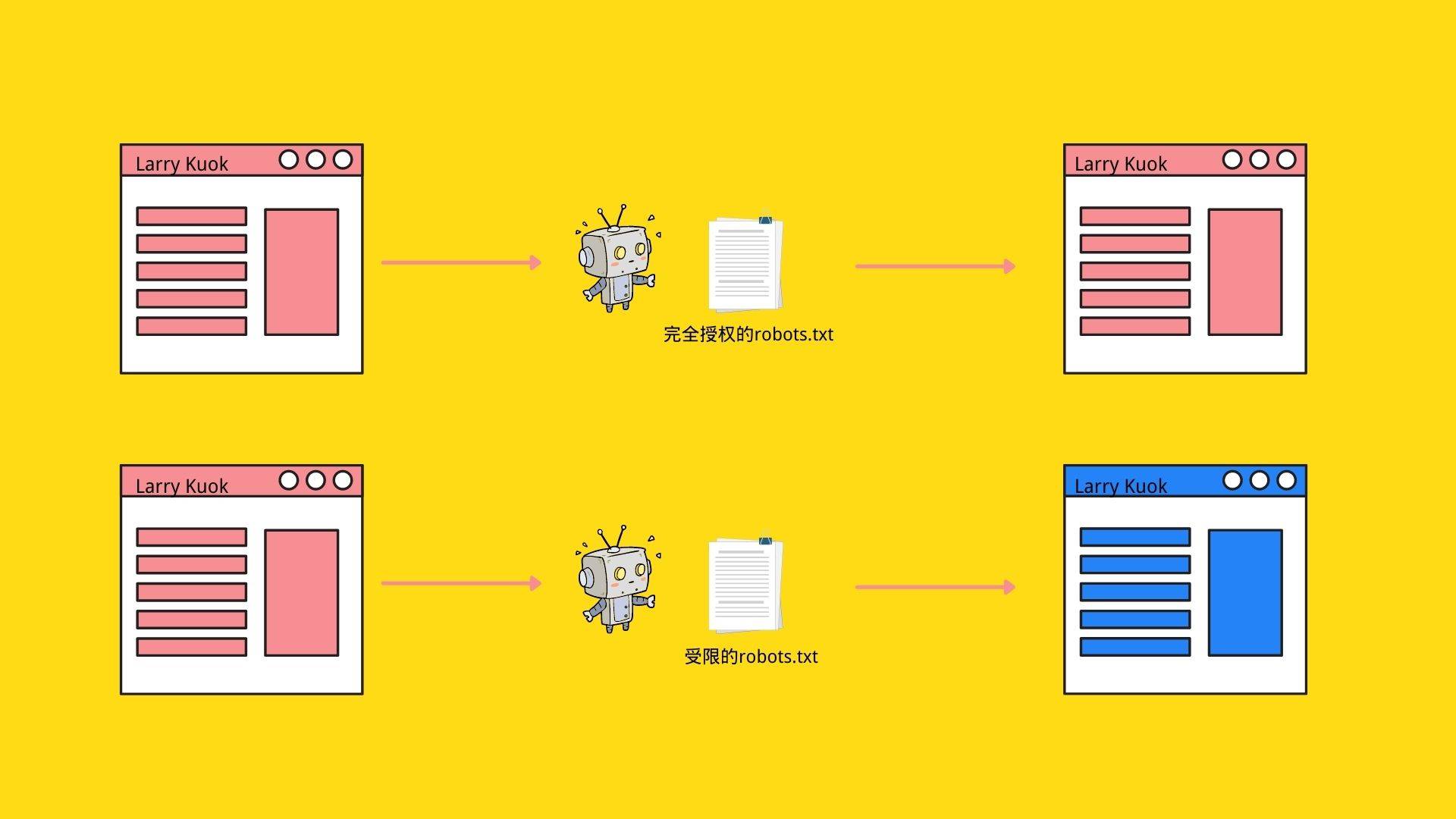
如我画这个简易的过程图所示,Googlebot为了做到向用户呈现网站设计者原本设计的网页样式内容,他们需要访问用于构建页面的所有资源文件。这需要在Robots.txt获取授权(大部分都是默认全部访问),但是除了网站管理者希望禁止抓取的内容,也存在各种错误配置或设置导致搜索引擎机器人无法访问到页面资源文件的情况。
如果 robots.txt 中不允许使用这些网页资源网址,则意味着 Googlebot 可能无法正确呈现网页内容。谷歌的许多算法都依赖于呈现——最显着的是“移动友好”算法(Mobile friendly algorithm)——所以如果内容无法正确呈现,这可能会对搜索引擎排名产生影响。
由于现在大部分



